Here we consider problem 6 of the recent Romanian Master of Mathematics competition – a very difficult problem. Nobody solved it during the tournament. Let me point out a very similar problem – RMM Shortlist 2020, A1 – see [3], proposed by the same author. I think it’s of similar difficulty. In my opinion both are not suitable for a high school Olympiad level, although I like them because it’s real math. Maybe they fit for Miklos Schweitzer competition, but on the other hand both problems are known results – the current one by Filaseta and Konyagin – see [2] – so the papers can easily be found by searching the web.
Problem (RMM 2024, problem 6). A polynomial 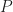 with integer coefficients is square-free if it is not expressible in the form
with integer coefficients is square-free if it is not expressible in the form  , where
, where 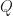 and
and  are polynomials with integer coefficients and is not constant. For a positive integer
are polynomials with integer coefficients and is not constant. For a positive integer  , let
, let 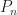 be the set of polynomials of the form
be the set of polynomials of the form

Prove that there exists an integer  such that for all integers
such that for all integers  , more than
, more than  of the polynomials in are square-free.
of the polynomials in are square-free.
(Navid Safaei, Iran)
The proof is based on the ideas I saw in [4] and consists of 3 main statements. The proof of the last one is a version of a problem we did in a blogpost here – see [1].
It boils down to prove that if we take a random polynomial in  the probability that it is not square-free tends to
the probability that it is not square-free tends to  as
as  Hereafter, we refer to polynomials in that are not square-free as bad polynomials, and to the square-free ones as good. So, in other words, if we take a random polynomial in the probability that it is bad tends to as Here are the milestones of our plan.
Hereafter, we refer to polynomials in that are not square-free as bad polynomials, and to the square-free ones as good. So, in other words, if we take a random polynomial in the probability that it is bad tends to as Here are the milestones of our plan.
- Claim 1. We’ll show that if we fix a natural number
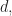 the probability of taking a bad polynomial in with
the probability of taking a bad polynomial in with  and
and  can be made as small as we want if
can be made as small as we want if 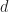 is large enough.
is large enough.
- Claim 2. We prove that there are finitely many with integer coefficients and
 for which there exists and
for which there exists and  such that
such that 
- Claim 3. We prove that for each fixed polynomial with integer coefficients
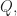 the probability of taking a polynomial so that
the probability of taking a polynomial so that 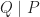 tends to as
tends to as
Suppose that we already have the above three claims proven. The second claim ensures that there are only finitely many integer polynomials  with degrees less than that can divide a binary polynomial .
with degrees less than that can divide a binary polynomial .
For any fixed we take a random polynomial and let us introduce the following events. Hereafter, denotes a polynomial with integer coefficients.




Apparently,

which implies

Fix some  The first claim shows that we can choose sufficiently large such that for any
The first claim shows that we can choose sufficiently large such that for any  we have
we have  According to the third claim, we can choose
According to the third claim, we can choose 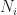 such that for
such that for  we have
we have 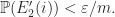 Therefore, for
Therefore, for  we have
we have

This means that the probability of taking a bad polynomial can be made as small as we want by choosing a sufficiently large 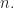 It remains to prove the three statements.
It remains to prove the three statements.
Proof of Claim 1. Dealing with large squares dividing binary polynomials.
Let be a natural number. Hereafter, and denote polynomial with integer coefficients and is a binary polynomial of degree Suppose where 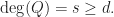 We reduce the polynomials
We reduce the polynomials  modulo 2, i.e. we substitute each coefficient with its residue modulo 2, thus obtaining new polynomials
modulo 2, i.e. we substitute each coefficient with its residue modulo 2, thus obtaining new polynomials  ( remains the same). Clearly
( remains the same). Clearly

We can assume that is a monic polynomial, hence  Clearly,
Clearly,  Since
Since  has
has 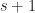 binary coefficients and
binary coefficients and  has
has  ones, all possible options for them are
ones, all possible options for them are  Thus, the number of polynomials that satisfies
Thus, the number of polynomials that satisfies 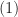 is at most
is at most  Therefore,
Therefore,

This yields,

which proves Claim 1.
Proof of Claim 2. Only finitely many “small” polynomials can divide a binary polynomial.
Let be a binary polynomial of degree First to see that all roots of lie in the disk  Assume on the contrary
Assume on the contrary  and
and  Then
Then


contradiction. Suppose now  and the senior coefficient of is
and the senior coefficient of is  Let
Let  are the roots of . The magnitude of all of them is less than
are the roots of . The magnitude of all of them is less than 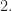 Using the Vieta formulas, we see that the coefficients of are less than some expression that depends only on
Using the Vieta formulas, we see that the coefficients of are less than some expression that depends only on  Since these coefficients are integers, the options for are finitely many, they are bounded by some constant that depends only on but not on
Since these coefficients are integers, the options for are finitely many, they are bounded by some constant that depends only on but not on
Proof of Claim 3. The probability that a binary polynomial is a multiple of a fixed polynomial is small.
Let be a fixed polynomial of integer coefficients and suppose  Let
Let 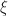 be a root of
be a root of  It follows
It follows  Note that
Note that  that’s why
that’s why 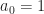 in the definition of
in the definition of  Take the set
Take the set  . Let us first consider the case when
. Let us first consider the case when  , i.e. is not a root of unity. The equality
, i.e. is not a root of unity. The equality
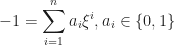
just means that the sum of elements of some subset of  is
is 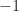
Lemma 1. Let be a set of distinct complex numbers and  The probability that the sum of the elements of a random subset of is
The probability that the sum of the elements of a random subset of is  is less than
is less than 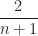 .
.
Proof. I considered and proved this claim in a blog post, see [1]. Call a subset of bad if the sum of its elements is 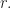 As usual, a subset of can be represented as a binary vector
As usual, a subset of can be represented as a binary vector  each bit indicates if an element is in the set or not. The idea is simple. For any binary vector
each bit indicates if an element is in the set or not. The idea is simple. For any binary vector 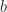 that corresponds to a bad subset we consider the unit sphere (by Hamming distance) centered at , that is, the set of all binary vectors that differ from at exactly one bit. Their number is Non of them is a bad binary vector. That is, each bad binary vector is surrounded by good ones. A bit care is needed to ensure that the unit spheres corresponding to distinct bad vectors do not intersect – see in [1]. So, the estimate follows.
that corresponds to a bad subset we consider the unit sphere (by Hamming distance) centered at , that is, the set of all binary vectors that differ from at exactly one bit. Their number is Non of them is a bad binary vector. That is, each bad binary vector is surrounded by good ones. A bit care is needed to ensure that the unit spheres corresponding to distinct bad vectors do not intersect – see in [1]. So, the estimate follows. 
Claim 3 follows from Lemma 1 if 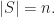 It remains to consider the case when is a multiset. Note that
It remains to consider the case when is a multiset. Note that  since
since  Let
Let  be he the smallest number with
be he the smallest number with 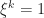 . We have a multiset with groups, each one consists of (almost)
. We have a multiset with groups, each one consists of (almost) 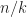 equal values. If is large (e.g.
equal values. If is large (e.g.  ), we can do the same trick as in Lemma 1 (flipping the bit of the first element of each group – we can number them) and obtain that the probability of taking a bad binary vector is less than
), we can do the same trick as in Lemma 1 (flipping the bit of the first element of each group – we can number them) and obtain that the probability of taking a bad binary vector is less than  .
.
In case is small ( ), we take the group
), we take the group  with the largest number of elements, say
with the largest number of elements, say  . Take a bad binary vector and let the number of chosen elements that are in is
. Take a bad binary vector and let the number of chosen elements that are in is  . Since all the elements in are the same (they have the same value), every binary vector with the same bits as outside , and such that the number of 1’s bits corresponding to the elements of is different from is not bad. So, the portion of the bad vectors for any fixed binary values corresponding to elements outside is at most
. Since all the elements in are the same (they have the same value), every binary vector with the same bits as outside , and such that the number of 1’s bits corresponding to the elements of is different from is not bad. So, the portion of the bad vectors for any fixed binary values corresponding to elements outside is at most
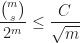 .
.
where  is a constant. Therefore, the probability of taking a bad binary vector is less than
is a constant. Therefore, the probability of taking a bad binary vector is less than ![\displaystyle \frac{C}{\sqrt m}\le \frac{C}{\sqrt[4]{n}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7BC%7D%7B%5Csqrt+m%7D%5Cle+%5Cfrac%7BC%7D%7B%5Csqrt%5B4%5D%7Bn%7D%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
This means that for a fixed polynomial , the probability of randomly taken is multiple of is  so it tends to zero as
so it tends to zero as 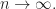
Comment
This solution has several crucial moments. The most difficult part (in my opinion) is to see that the probability of a binary polynomial be multiple of  where is an integer polynomial of some large degree, is small (it’s
where is an integer polynomial of some large degree, is small (it’s  ). It involves a reduction modulo
). It involves a reduction modulo  . The second part is to see that there are only finitely many polynomials with small degrees that can divide some binary polynomial
. The second part is to see that there are only finitely many polynomials with small degrees that can divide some binary polynomial  To see this we bound their coefficients. This is not hard to see, but it’s meaningful only if you got the first idea. In the third place comes the idea that for any fixed , the portion of the binary polynomials multiple of tends to as
To see this we bound their coefficients. This is not hard to see, but it’s meaningful only if you got the first idea. In the third place comes the idea that for any fixed , the portion of the binary polynomials multiple of tends to as  . I would say that it’s doable in real time, but only if you get to that point.
. I would say that it’s doable in real time, but only if you get to that point.
References.
[1] Hamming distance in Olympiad problems. Part 2.
[2] Squarefree values of polynomials all of whose coefficients are 0 and 1, M. Filaseta, S. Konyagin, Acta Arith., 74(3): 191-205, 1996
[3] A polynomial with coefficients +/-1 very likely to be irreducible. RMM 2020 Shortlist.
[4] AoPS thread on this problem



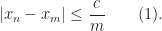

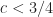
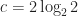
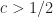

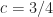
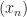

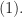


![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

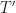

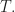

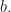
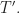
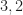

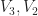
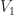
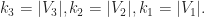
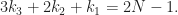
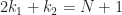


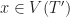
![x_n, n\in[1..N]](https://s0.wp.com/latex.php?latex=x_n%2C+n%5Cin%5B1..N%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

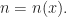


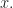
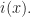
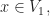
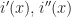

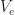

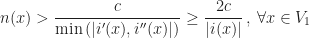


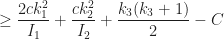


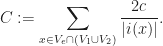









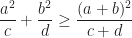
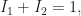





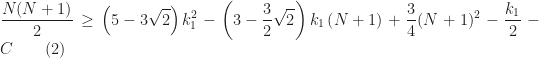
![\displaystyle f(k_1), k_1\in \left[0,(N+1)/2\right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+f%28k_1%29%2C+k_1%5Cin+%5Cleft%5B0%2C%28N%2B1%29%2F2%5Cright%5D.&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

![f'(k_1)\le 0, \forall k_1\in \left[0,(N+1)/2\right],](https://s0.wp.com/latex.php?latex=f%27%28k_1%29%5Cle+0%2C+%5Cforall+k_1%5Cin+%5Cleft%5B0%2C%28N%2B1%29%2F2%5Cright%5D%2C&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
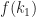
![[0,(N+1)/2],](https://s0.wp.com/latex.php?latex=%5B0%2C%28N%2B1%29%2F2%5D%2C&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
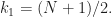


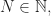
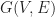 is given, without chords and
is given, without chords and  We want to prove the following statement
We want to prove the following statement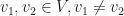 with
with  which have a common neighbour.
which have a common neighbour. 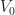 be the set of all vertices of degree exactly
be the set of all vertices of degree exactly 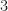 or more. Here are some observation based on our assumption.
or more. Here are some observation based on our assumption. and
and  then
then 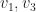 would satisfy (*).
would satisfy (*).

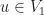 (see fig. 1) as a root and start constructing a spanning tree of
(see fig. 1) as a root and start constructing a spanning tree of 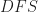 algorithm. Every time we hit a vertex, say
algorithm. Every time we hit a vertex, say  that is connected to a vertex in
that is connected to a vertex in  and bach to
and bach to  in case
in case  in case
in case  is connected to another vertex
is connected to another vertex 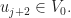

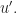 Since
Since  we have
we have 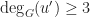 and thus
and thus  is connected (in
is connected (in 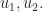 Since we used DFS algorithm, the vertices
Since we used DFS algorithm, the vertices  are comparable in
are comparable in  and
and 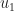 lie on the (unique) path from
lie on the (unique) path from  But then
But then  is a chord in the cycle
is a chord in the cycle  contradiction.
contradiction.  is given. The points
is given. The points  and
and  and
and 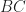 such that
such that  and
and  Let
Let  and
and 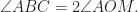 Find
Find 
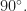 Denote
Denote  . We interpret the configuration as follows see fig. 1. Thanks to Nevena for the nice drawing! We have an isosceles triangle
. We interpret the configuration as follows see fig. 1. Thanks to Nevena for the nice drawing! We have an isosceles triangle  with
with 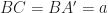 and
and 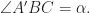 Initially
Initially 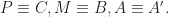 Then, the three points
Then, the three points 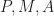 start moving with equal velocities, that is,
start moving with equal velocities, that is, 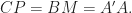 It ends when
It ends when  (
(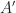 ).
).  the angle
the angle  is greater or equal to
is greater or equal to  . That is,
. That is, 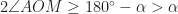 . The minimum value of
. The minimum value of  or when
or when  .
.  the angle
the angle 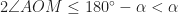 . The maximum value of
. The maximum value of  is possible is
is possible is  . In this case, it’s easy to see that
. In this case, it’s easy to see that 
 Clearly
Clearly 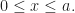 We construct additional points
We construct additional points  and
and  – see fig. 1 – such that:
– see fig. 1 – such that: 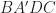 is a rhombus,
is a rhombus,  and
and  In fact, we translate
In fact, we translate 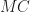 to
to 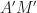 and
and  to
to 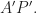
 . Denote
. Denote  and
and  . It’s enough to prove
. It’s enough to prove  In order to do it we prove
In order to do it we prove 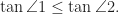 It easily follows that
It easily follows that 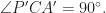 Let
Let  A bit of calculation needed. We have
A bit of calculation needed. We have  so it follows
so it follows
 and
and  we get,
we get,
 (
( or
or 
 is
is  It can be easily proved (with the same technique as above) that in this case
It can be easily proved (with the same technique as above) that in this case 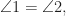 that is,
that is,  By the way, you don’t need to worry about it. You only need just one example for which the configuration is valid, and it is obviously true when
By the way, you don’t need to worry about it. You only need just one example for which the configuration is valid, and it is obviously true when 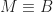 or
or 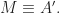
 for some constants
for some constants  The point is that in this case, starting from an edge, you can reach any other edge passing through at most one intermediate edge. So, it’s more interesting to see what happens when the graph has fewer edges, for example if it is a tree. This is an interesting question, and it turns out that in this case
The point is that in this case, starting from an edge, you can reach any other edge passing through at most one intermediate edge. So, it’s more interesting to see what happens when the graph has fewer edges, for example if it is a tree. This is an interesting question, and it turns out that in this case 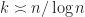 . The next problem is a version of this question asked for a complete binary graph. Note that the lower bound is not hard. The main difficulty is to construct a list in case
. The next problem is a version of this question asked for a complete binary graph. Note that the lower bound is not hard. The main difficulty is to construct a list in case  .
. knights to an audience in Camelot. Merlin the Magician arranged the knights in a list numbered from
knights to an audience in Camelot. Merlin the Magician arranged the knights in a list numbered from  are friends if and only if
are friends if and only if  . The king chose a natural number
. The king chose a natural number 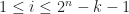 , all friends of the knight with sequence number
, all friends of the knight with sequence number  (in the new list) must be in positions among
(in the new list) must be in positions among  . Prove that the smallest
. Prove that the smallest 
 as King Arthur requested, where
as King Arthur requested, where 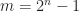 and
and 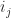 refers to the label of the corresponding vertex. There is a unique path in
refers to the label of the corresponding vertex. There is a unique path in 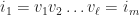 that connects the vertex labeled as
that connects the vertex labeled as 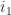 and
and  . Clearly,
. Clearly,  , because the longest path in
, because the longest path in 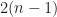 . Note that the distance between the positions of
. Note that the distance between the positions of  and
and  in the new list, is at most
in the new list, is at most 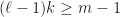 which yields
which yields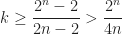
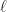 be a natural number which will be determined later. Denote by
be a natural number which will be determined later. Denote by  the vertices of
the vertices of  be the subtrees with roots in these points – see fig. 1. Each of them has exactly
be the subtrees with roots in these points – see fig. 1. Each of them has exactly  leaves.
leaves.
 , that is, its leaves. Then we put down the second to last level of
, that is, its leaves. Then we put down the second to last level of  . At the
. At the  -th level of
-th level of 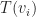 (i.e. its leaves). The number of vertices we place at the
(i.e. its leaves). The number of vertices we place at the  is equal to
is equal to
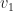 of
of  .
. 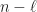 steps and the second one – after
steps and the second one – after  steps. To ensure that the second event occurs first we choose
steps. To ensure that the second event occurs first we choose  .
.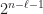 . The number of vertices in
. The number of vertices in  without its last two layers does not exceed
without its last two layers does not exceed  and so on. Adding the vertices of
and so on. Adding the vertices of 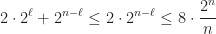
 . Clearly, for any vertex
. Clearly, for any vertex  , placed at position
, placed at position 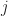 in the first
in the first  . Taking into account the number of vertices added in the last step, we get that in the constructed list the condition imposed by the king holds for
. Taking into account the number of vertices added in the last step, we get that in the constructed list the condition imposed by the king holds for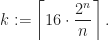
 1) If
1) If 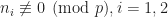 then
then  2) For any integers
2) For any integers  with
with  we have
we have 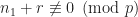 or
or 

 of all residues
of all residues  modulo
modulo 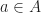 and considers the set
and considers the set  It follows from very basic facts that all these numbers give distinct residues modulo
It follows from very basic facts that all these numbers give distinct residues modulo  and all of them are coprime with
and all of them are coprime with 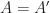 , that is, the second system of residues is just a permutation of the first one. Multiplying the elements in
, that is, the second system of residues is just a permutation of the first one. Multiplying the elements in 
 (by the definition of
(by the definition of  ), the result in
), the result in  . Let
. Let  be a list of positive integers less than
be a list of positive integers less than 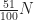 times and
times and  is not divisible by
is not divisible by  of the
of the 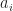 such that, for all
such that, for all 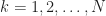 , the sum
, the sum  is not divisible by
is not divisible by  ) that satisfies the condition
) that satisfies the condition
 that satisfies the problem’s condition. This arrangement can be done via a greedy algorithm with a little bit common sense. Here it is.
that satisfies the problem’s condition. This arrangement can be done via a greedy algorithm with a little bit common sense. Here it is.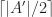 times. We try to pick this value, and if we cannot do this, because we would hit
times. We try to pick this value, and if we cannot do this, because we would hit  , put it in the row and we put
, put it in the row and we put  . Thus, we comply with the given condition and we are at position with a multiset
. Thus, we comply with the given condition and we are at position with a multiset 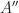 that consists of
that consists of  elements. The point is that
elements. The point is that  times. This time we want
times. This time we want  . So,
. So,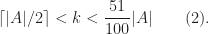
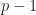 of them, one after another in a row. Any partial sum of this row is not
of them, one after another in a row. Any partial sum of this row is not  and the fact that
and the fact that 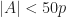 , it easily follows that the remaining elements form a multiset
, it easily follows that the remaining elements form a multiset  and
and  be the (non-negative) remainder that
be the (non-negative) remainder that  leaves upon division by
leaves upon division by  . Assume there exists a positive integer
. Assume there exists a positive integer 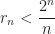 for all integers
for all integers 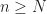 . Prove that
. Prove that  Hence,
Hence,  where
where  and
and  . In this case we’ll prove something stronger. Namely, it’s even not possible that
. In this case we’ll prove something stronger. Namely, it’s even not possible that  , where
, where  , that is, it’s not possible that
, that is, it’s not possible that  .
.
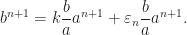

 denotes the fractional part. Now, for sufficiently large
denotes the fractional part. Now, for sufficiently large  since
since  . Note that
. Note that  is either integer or its distance to the nearest integer is at least
is either integer or its distance to the nearest integer is at least  It gives us
It gives us  This leads us to contradiction if we take a special
This leads us to contradiction if we take a special 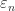 such that
such that  It is possible since
It is possible since 
 and
and  we can find infinitely many
we can find infinitely many  for some constant
for some constant  be a function satisfying
be a function satisfying

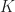 be a convex set inside some real vector space
be a convex set inside some real vector space  . We say
. We say 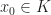 is an extreme point (also called a corner point) of
is an extreme point (also called a corner point) of 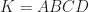 whose extreme points are the vertices
whose extreme points are the vertices  (in red). All the other points of
(in red). All the other points of 
 is a compact convex set. Then
is a compact convex set. Then  by setting
by setting  so that the new function satisfies
so that the new function satisfies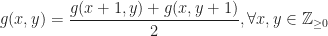

 the vector space of all real valued functions on the lattice
the vector space of all real valued functions on the lattice  Note that by
Note that by  and
and  and by induction we get
and by induction we get
 and any
and any  Also, it easily follows that
Also, it easily follows that  Hence,
Hence,  Let us determine the extreme points of
Let us determine the extreme points of  is such point. Denote
is such point. Denote  Suppose for example
Suppose for example  In this case it straightforward follows
In this case it straightforward follows 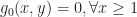 and
and  Assuming
Assuming  implies
implies  and
and 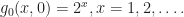 It can be checked that these two functions are indeed extreme points of
It can be checked that these two functions are indeed extreme points of 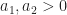 and consider the functions
and consider the functions
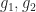 satisfy
satisfy 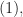 thus
thus  Observe that
Observe that  so
so  Further,
Further,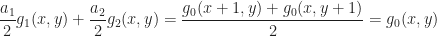
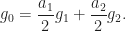
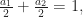 so
so  lies on the segment
lies on the segment ![[g_1,g_2].](https://s0.wp.com/latex.php?latex=%5Bg_1%2Cg_2%5D.&bg=ffffff&fg=1a1a1a&s=0&c=20201002) Therefore
Therefore  Assuming so,
Assuming so,  easily yields
easily yields 
 is an extreme point of
is an extreme point of  it must satisfy the above equality for some
it must satisfy the above equality for some  with
with  the set of these functions. They are indeed extreme points, but we don’t need to prove it for our purpose. What we need is that
the set of these functions. They are indeed extreme points, but we don’t need to prove it for our purpose. What we need is that
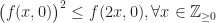 is equivalent to proving
is equivalent to proving
 Let
Let  and
and  where
where  We just need to check
We just need to check
 This immediately follows from Cauchy-Schwartz inequality applied to
This immediately follows from Cauchy-Schwartz inequality applied to 
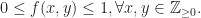 Let us fix a positive integer
Let us fix a positive integer 

 axes, taken at the point
axes, taken at the point  We have
We have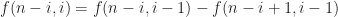


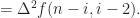


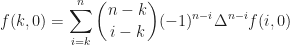
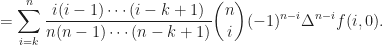


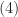 it follows
it follows
 which folows from
which folows from 
 the sum in the right hand side of the above inequality is
the sum in the right hand side of the above inequality is 


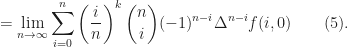

 , we obtain
, we obtain
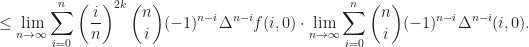


 of subsets of
of subsets of ![[n],](https://s0.wp.com/latex.php?latex=%5Bn%5D%2C&bg=ffffff&fg=1a1a1a&s=0&c=20201002) such that for any nonempty subset
such that for any nonempty subset ![X\subseteq [n]](https://s0.wp.com/latex.php?latex=X%5Csubseteq+%5Bn%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) , exactly half of the elements
, exactly half of the elements  satisfy that
satisfy that  is even.
is even.![[n].](https://s0.wp.com/latex.php?latex=%5Bn%5D.&bg=ffffff&fg=1a1a1a&s=0&c=20201002) The idea is to balance the number of even and odd values of
The idea is to balance the number of even and odd values of ![A\in \mathcal F, X\subset [n].](https://s0.wp.com/latex.php?latex=A%5Cin+%5Cmathcal+F%2C+X%5Csubset+%5Bn%5D.&bg=ffffff&fg=1a1a1a&s=0&c=20201002) It’s useful to introduce a notation that indicates whether
It’s useful to introduce a notation that indicates whether 
 thus
thus  Consider now the following sum
Consider now the following sum![\displaystyle S:= \sum_{A\in \mathcal{F}\,,\, X\subset [n]}\, P(A\cap X)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+S%3A%3D+%5Csum_%7BA%5Cin+%5Cmathcal%7BF%7D%5C%2C%2C%5C%2C+X%5Csubset+%5Bn%5D%7D%5C%2C+P%28A%5Ccap+X%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![X \subset [n]](https://s0.wp.com/latex.php?latex=X+%5Csubset+%5Bn%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) , and then fixing
, and then fixing  Note that if
Note that if  then
then![\displaystyle \sum_{X\subset [n]} P(A\cap X)= 0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7BX%5Csubset+%5Bn%5D%7D+P%28A%5Ccap+X%29%3D+0&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 this sum is equal to
this sum is equal to 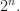
![\displaystyle S= \sum_{A\in \mathcal{F}} \sum_{X\subset [n]} P(A\cap X).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+S%3D+%5Csum_%7BA%5Cin+%5Cmathcal%7BF%7D%7D+%5Csum_%7BX%5Csubset+%5Bn%5D%7D+P%28A%5Ccap+X%29.&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
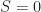 in case
in case  and
and  otherwise.
otherwise.![\displaystyle S= \sum_{X\subset [n]}\sum_{A\in \mathcal{F}} P(A\cap X).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+S%3D+%5Csum_%7BX%5Csubset+%5Bn%5D%7D%5Csum_%7BA%5Cin+%5Cmathcal%7BF%7D%7D+P%28A%5Ccap+X%29.&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
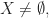 the internal sum equals
the internal sum equals  Hence,
Hence,  Since
Since  is not empty, we get
is not empty, we get  thus
thus ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) or it is empty.
or it is empty.![X\subset [n]](https://s0.wp.com/latex.php?latex=X%5Csubset+%5Bn%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) as a binary vector
as a binary vector 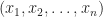 such that
such that  if
if 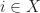 and
and  otherwise. Suppose that
otherwise. Suppose that  and a binary vector
and a binary vector  that represents a subset
that represents a subset ![X\subset [n],](https://s0.wp.com/latex.php?latex=X%5Csubset+%5Bn%5D%2C&bg=ffffff&fg=1a1a1a&s=0&c=20201002) the following expression
the following expression

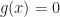 for every binary vector
for every binary vector  For this value we have
For this value we have

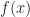 is zero for every binary vector
is zero for every binary vector ![[n]\notin \mathcal F.](https://s0.wp.com/latex.php?latex=%5Bn%5D%5Cnotin+%5Cmathcal+F.&bg=ffffff&fg=1a1a1a&s=0&c=20201002) Then the monomial
Then the monomial  is present only in the first product in the right hand side of
is present only in the first product in the right hand side of  i.e. it’s non-zero. By Combinatorial Nullstellensatz, there exists a binary vector
i.e. it’s non-zero. By Combinatorial Nullstellensatz, there exists a binary vector  such that
such that  conradiction.
conradiction.![[n]\in\mathcal F.](https://s0.wp.com/latex.php?latex=%5Bn%5D%5Cin%5Cmathcal+F.&bg=ffffff&fg=1a1a1a&s=0&c=20201002) Then the coefficient in front of
Then the coefficient in front of  is
is  So, the coefficient of this monomial in
So, the coefficient of this monomial in  If this value is not zero, we get the same contradiction. Therefore
If this value is not zero, we get the same contradiction. Therefore 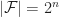 and
and  and
and 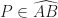 be a point such that its Simson line
be a point such that its Simson line  touches the Euler circle
touches the Euler circle  . Note that the center
. Note that the center  of the Euler circle of
of the Euler circle of  (
(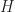 is the orthocenter of
is the orthocenter of  is the midpoint of
is the midpoint of  .
.
 is a midsegment in
is a midsegment in  . Tre radius
. Tre radius  is perpendicular t0
is perpendicular t0  that the line
that the line  easily follows from the homothety
easily follows from the homothety  .
.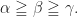
 (notice that
(notice that  and
and  ).
).
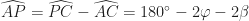 and
and 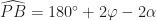 .
. it follows that
it follows that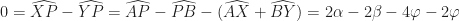 ,
, .
. be these points and
be these points and  be their Simson lines.
be their Simson lines. 
 and
and  , we get
, we get 
