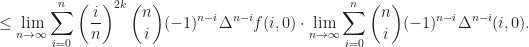Here we consider problem 6 of the recent Romanian Master of Mathematics competition – a very difficult problem. Nobody solved it during the tournament. Let me point out a very similar problem – RMM Shortlist 2020, A1 – see [3], proposed by the same author. I think it’s of similar difficulty. In my opinion both are not suitable for a high school Olympiad level, although I like them because it’s real math. Maybe they fit for Miklos Schweitzer competition, but on the other hand both problems are known results – the current one by Filaseta and Konyagin – see [2] – so the papers can easily be found by searching the web.
Problem (RMM 2024, problem 6). A polynomial  with integer coefficients is square-free if it is not expressible in the form
with integer coefficients is square-free if it is not expressible in the form  , where
, where  and
and  are polynomials with integer coefficients and is not constant. For a positive integer
are polynomials with integer coefficients and is not constant. For a positive integer  , let
, let  be the set of polynomials of the form
be the set of polynomials of the form

Prove that there exists an integer  such that for all integers
such that for all integers  , more than
, more than  of the polynomials in are square-free.
of the polynomials in are square-free.
(Navid Safaei, Iran)
The proof is based on the ideas I saw in [4] and consists of 3 main statements. The proof of the last one is a version of a problem we did in a blogpost here – see [1].
It boils down to prove that if we take a random polynomial in  the probability that it is not square-free tends to
the probability that it is not square-free tends to  as
as  Hereafter, we refer to polynomials in that are not square-free as bad polynomials, and to the square-free ones as good. So, in other words, if we take a random polynomial in the probability that it is bad tends to as Here are the milestones of our plan.
Hereafter, we refer to polynomials in that are not square-free as bad polynomials, and to the square-free ones as good. So, in other words, if we take a random polynomial in the probability that it is bad tends to as Here are the milestones of our plan.
- Claim 1. We’ll show that if we fix a natural number
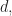 the probability of taking a bad polynomial in with
the probability of taking a bad polynomial in with  and
and  can be made as small as we want if
can be made as small as we want if 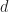 is large enough.
is large enough.
- Claim 2. We prove that there are finitely many with integer coefficients and
 for which there exists and
for which there exists and  such that
such that 
- Claim 3. We prove that for each fixed polynomial with integer coefficients
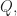 the probability of taking a polynomial so that
the probability of taking a polynomial so that 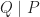 tends to as
tends to as
Suppose that we already have the above three claims proven. The second claim ensures that there are only finitely many integer polynomials  with degrees less than that can divide a binary polynomial .
with degrees less than that can divide a binary polynomial .
For any fixed we take a random polynomial and let us introduce the following events. Hereafter, denotes a polynomial with integer coefficients.




Apparently,

which implies

Fix some  The first claim shows that we can choose sufficiently large such that for any
The first claim shows that we can choose sufficiently large such that for any  we have
we have  According to the third claim, we can choose
According to the third claim, we can choose 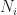 such that for
such that for  we have
we have 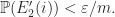 Therefore, for
Therefore, for  we have
we have

This means that the probability of taking a bad polynomial can be made as small as we want by choosing a sufficiently large 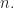 It remains to prove the three statements.
It remains to prove the three statements.
Proof of Claim 1. Dealing with large squares dividing binary polynomials.
Let be a natural number. Hereafter, and denote polynomial with integer coefficients and is a binary polynomial of degree Suppose where 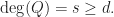 We reduce the polynomials
We reduce the polynomials  modulo 2, i.e. we substitute each coefficient with its residue modulo 2, thus obtaining new polynomials
modulo 2, i.e. we substitute each coefficient with its residue modulo 2, thus obtaining new polynomials  ( remains the same). Clearly
( remains the same). Clearly

We can assume that is a monic polynomial, hence  Clearly,
Clearly,  Since
Since  has
has 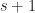 binary coefficients and
binary coefficients and  has
has  ones, all possible options for them are
ones, all possible options for them are  Thus, the number of polynomials that satisfies
Thus, the number of polynomials that satisfies 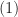 is at most
is at most  Therefore,
Therefore,

This yields,

which proves Claim 1.
Proof of Claim 2. Only finitely many “small” polynomials can divide a binary polynomial.
Let be a binary polynomial of degree First to see that all roots of lie in the disk  Assume on the contrary
Assume on the contrary  and
and  Then
Then


contradiction. Suppose now  and the senior coefficient of is
and the senior coefficient of is  Let
Let  are the roots of . The magnitude of all of them is less than
are the roots of . The magnitude of all of them is less than 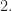 Using the Vieta formulas, we see that the coefficients of are less than some expression that depends only on
Using the Vieta formulas, we see that the coefficients of are less than some expression that depends only on  Since these coefficients are integers, the options for are finitely many, they are bounded by some constant that depends only on but not on
Since these coefficients are integers, the options for are finitely many, they are bounded by some constant that depends only on but not on
Proof of Claim 3. The probability that a binary polynomial is a multiple of a fixed polynomial is small.
Let be a fixed polynomial of integer coefficients and suppose  Let
Let 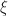 be a root of
be a root of  It follows
It follows  Note that
Note that  that’s why
that’s why 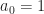 in the definition of
in the definition of  Take the set
Take the set  . Let us first consider the case when
. Let us first consider the case when  , i.e. is not a root of unity. The equality
, i.e. is not a root of unity. The equality
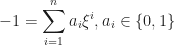
just means that the sum of elements of some subset of  is
is 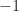
Lemma 1. Let be a set of distinct complex numbers and  The probability that the sum of the elements of a random subset of is
The probability that the sum of the elements of a random subset of is  is less than
is less than 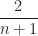 .
.
Proof. I considered and proved this claim in a blog post, see [1]. Call a subset of bad if the sum of its elements is 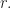 As usual, a subset of can be represented as a binary vector
As usual, a subset of can be represented as a binary vector  each bit indicates if an element is in the set or not. The idea is simple. For any binary vector
each bit indicates if an element is in the set or not. The idea is simple. For any binary vector 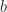 that corresponds to a bad subset we consider the unit sphere (by Hamming distance) centered at , that is, the set of all binary vectors that differ from at exactly one bit. Their number is Non of them is a bad binary vector. That is, each bad binary vector is surrounded by good ones. A bit care is needed to ensure that the unit spheres corresponding to distinct bad vectors do not intersect – see in [1]. So, the estimate follows.
that corresponds to a bad subset we consider the unit sphere (by Hamming distance) centered at , that is, the set of all binary vectors that differ from at exactly one bit. Their number is Non of them is a bad binary vector. That is, each bad binary vector is surrounded by good ones. A bit care is needed to ensure that the unit spheres corresponding to distinct bad vectors do not intersect – see in [1]. So, the estimate follows. 
Claim 3 follows from Lemma 1 if 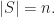 It remains to consider the case when is a multiset. Note that
It remains to consider the case when is a multiset. Note that  since
since  Let
Let  be he the smallest number with
be he the smallest number with 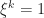 . We have a multiset with groups, each one consists of (almost)
. We have a multiset with groups, each one consists of (almost) 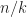 equal values. If is large (e.g.
equal values. If is large (e.g.  ), we can do the same trick as in Lemma 1 (flipping the bit of the first element of each group – we can number them) and obtain that the probability of taking a bad binary vector is less than
), we can do the same trick as in Lemma 1 (flipping the bit of the first element of each group – we can number them) and obtain that the probability of taking a bad binary vector is less than  .
.
In case is small ( ), we take the group
), we take the group  with the largest number of elements, say
with the largest number of elements, say  . Take a bad binary vector and let the number of chosen elements that are in is
. Take a bad binary vector and let the number of chosen elements that are in is  . Since all the elements in are the same (they have the same value), every binary vector with the same bits as outside , and such that the number of 1’s bits corresponding to the elements of is different from is not bad. So, the portion of the bad vectors for any fixed binary values corresponding to elements outside is at most
. Since all the elements in are the same (they have the same value), every binary vector with the same bits as outside , and such that the number of 1’s bits corresponding to the elements of is different from is not bad. So, the portion of the bad vectors for any fixed binary values corresponding to elements outside is at most
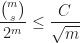 .
.
where  is a constant. Therefore, the probability of taking a bad binary vector is less than
is a constant. Therefore, the probability of taking a bad binary vector is less than ![\displaystyle \frac{C}{\sqrt m}\le \frac{C}{\sqrt[4]{n}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7BC%7D%7B%5Csqrt+m%7D%5Cle+%5Cfrac%7BC%7D%7B%5Csqrt%5B4%5D%7Bn%7D%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
This means that for a fixed polynomial , the probability of randomly taken is multiple of is  so it tends to zero as
so it tends to zero as 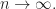
Comment
This solution has several crucial moments. The most difficult part (in my opinion) is to see that the probability of a binary polynomial be multiple of  where is an integer polynomial of some large degree, is small (it’s
where is an integer polynomial of some large degree, is small (it’s  ). It involves a reduction modulo
). It involves a reduction modulo  . The second part is to see that there are only finitely many polynomials with small degrees that can divide some binary polynomial
. The second part is to see that there are only finitely many polynomials with small degrees that can divide some binary polynomial  To see this we bound their coefficients. This is not hard to see, but it’s meaningful only if you got the first idea. In the third place comes the idea that for any fixed , the portion of the binary polynomials multiple of tends to as
To see this we bound their coefficients. This is not hard to see, but it’s meaningful only if you got the first idea. In the third place comes the idea that for any fixed , the portion of the binary polynomials multiple of tends to as  . I would say that it’s doable in real time, but only if you get to that point.
. I would say that it’s doable in real time, but only if you get to that point.
References.
[1] Hamming distance in Olympiad problems. Part 2.
[2] Squarefree values of polynomials all of whose coefficients are 0 and 1, M. Filaseta, S. Konyagin, Acta Arith., 74(3): 191-205, 1996
[3] A polynomial with coefficients +/-1 very likely to be irreducible. RMM 2020 Shortlist.
[4] AoPS thread on this problem

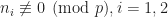



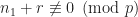




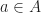


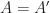
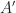





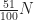


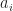
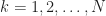




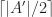


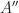



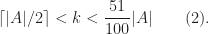
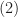
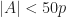





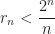
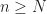








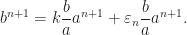







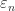





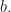
 be a function satisfying
be a function satisfying

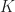 be a convex set inside some real vector space
be a convex set inside some real vector space  . We say
. We say 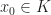 is an extreme point (also called a corner point) of
is an extreme point (also called a corner point) of 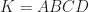 whose extreme points are the vertices
whose extreme points are the vertices  (in red). All the other points of
(in red). All the other points of 
 is a compact convex set. Then
is a compact convex set. Then  by setting
by setting  so that the new function satisfies
so that the new function satisfies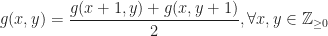

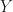 the vector space of all real valued functions on the lattice
the vector space of all real valued functions on the lattice  Note that by
Note that by  and
and  and by induction we get
and by induction we get
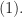 Thus,
Thus, 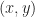 and any
and any  Also, it easily follows that
Also, it easily follows that  Hence,
Hence,  Let us determine the extreme points of
Let us determine the extreme points of  is such point. Denote
is such point. Denote  Suppose for example
Suppose for example 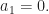 In this case it straightforward follows
In this case it straightforward follows 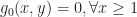 and
and  Assuming
Assuming  implies
implies  and
and 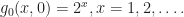 It can be checked that these two functions are indeed extreme points of
It can be checked that these two functions are indeed extreme points of  and consider the functions
and consider the functions
 satisfy
satisfy  thus
thus  Observe that
Observe that  so
so  Further,
Further,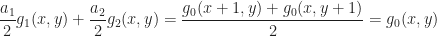
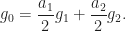
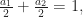 so
so  lies on the segment
lies on the segment ![[g_1,g_2].](https://s0.wp.com/latex.php?latex=%5Bg_1%2Cg_2%5D.&bg=ffffff&fg=1a1a1a&s=0&c=20201002) Therefore
Therefore  Assuming so,
Assuming so,  easily yields
easily yields 
 is an extreme point of
is an extreme point of 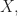 it must satisfy the above equality for some
it must satisfy the above equality for some  with
with  the set of these functions. They are indeed extreme points, but we don’t need to prove it for our purpose. What we need is that
the set of these functions. They are indeed extreme points, but we don’t need to prove it for our purpose. What we need is that
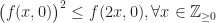 is equivalent to proving
is equivalent to proving
 Let
Let  and
and  where
where  We just need to check
We just need to check
 This immediately follows from Cauchy-Schwartz inequality applied to
This immediately follows from Cauchy-Schwartz inequality applied to 
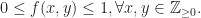 Let us fix a positive integer
Let us fix a positive integer 

 -th finite difference with step
-th finite difference with step  axes, taken at the point
axes, taken at the point  We have
We have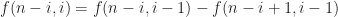


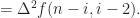


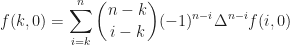
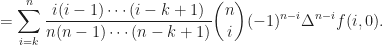


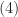 it follows
it follows
 which folows from
which folows from 
 the sum in the right hand side of the above inequality is
the sum in the right hand side of the above inequality is 


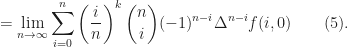

 , we obtain
, we obtain